LLaMA is a large foundational natural language model developed by Meta, which was publicly released for the first time on February 24th, 2023. According to information disclosed by Meta, LLaMA is divided into four sizes based on the number of training parameters: 7B, 13B, 33B, and 65B. Meta claims that models with 13B parameters or less can run on a single GPU, making it possible for others in the research community who lack access to significant infrastructure to study these models. This further democratizes access to this important and rapidly evolving field.
Meta said: “To maintain integrity and prevent misuse, we are releasing our model under a noncommercial license focused on research use cases. Access to the model will be granted on a case-by-case basis to academic researchers; those affiliated with organizations in government, civil society, and academia; and industry research laboratories around the world.”
Price: None Tag: AI Chatbot Release time: February 25, 2023 Developer(s): Meta
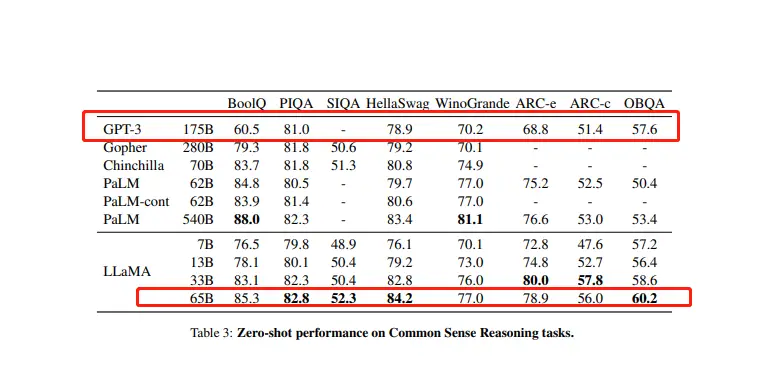
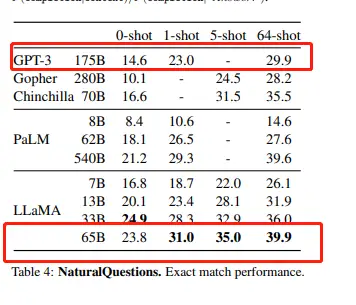
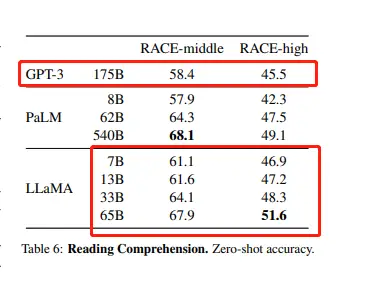
LLaMA, like other similar models, is capable of handling almost all types of text-related tasks. However, there are still some limitations to the model’s capabilities, as it may produce errors or generate toxic content. According to its official research paper, LLaMA outperforms GPT-3, which has 175 billion parameters, on most benchmarks, despite having a maximum of only 65 billion parameters. For example:
Reasoning
Answer Question
Reading Comprehension
For more technical information, please check LLaMA Paper.