What is OpenAI Batch API And What Can I Do with?


The OpenAI Batch API is an innovative service designed to facilitate bulk processing of AI tasks asynchronously. This API allows users to submit multiple queries or tasks in a single batch, which the system processes during off-peak times to optimize resource usage and reduce operational costs. Introduced as part of OpenAI’s efforts to enhance efficiency and accessibility, the Batch API supports large-scale operations without the need for immediate processing, ensuring a turnaround within 24 hours.
The OpenAI Batch API revolutionizes bulk AI processing by allowing asynchronous task management and cost-effective operations. With its new office in Tokyo, OpenAI customizes its offerings for the Japanese market, emphasizing local collaboration and innovation.
Table of Contents
How does the Batch API work?
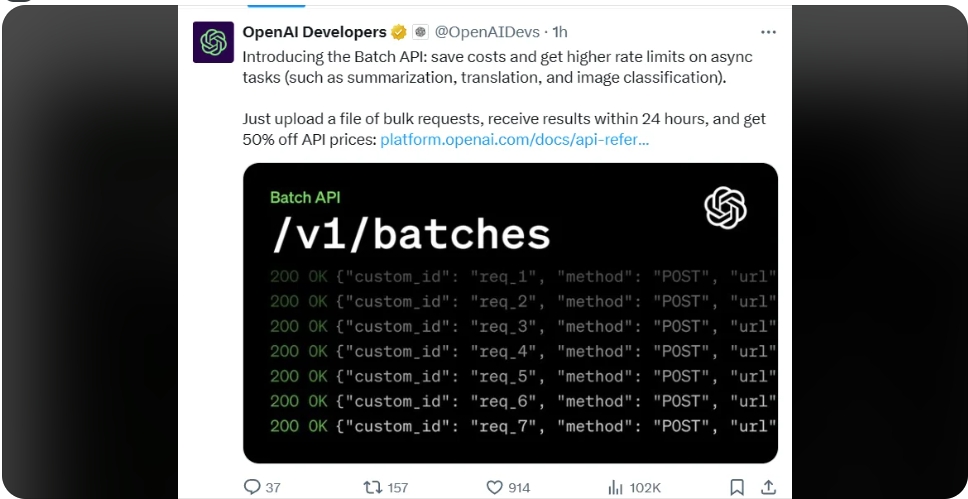
The Batch API from OpenAI simplifies the handling of large-scale AI operations by allowing bulk submissions of tasks that are processed asynchronously. This approach not only maximizes computational efficiency but also aligns with cost-effective strategies for large data handling. Let’s delve into the step-by-step process to understand its workings in detail.
Submitting a Batch
Users begin by submitting a batch, which consists of numerous requests compiled into a single file. This file should be formatted properly to ensure that the API can parse and queue each request correctly.
- Bulk Submission: Users can send hundreds or thousands of requests at once.
- File Format: The file must be in a JSONL format, where each line represents a separate request.
Processing the Requests
Once submitted, the requests are queued for processing during off-peak hours to optimize resource utilization and reduce operational costs.
- Asynchronous Processing: Tasks are processed when resources are least in demand.
- Resource Optimization: Efficient use of AI models and computational power.
Retrieving Results
After processing, the results are compiled and can be retrieved by the users. This typically happens within 24 hours, providing a convenient turnaround for batch operations.
- Result Compilation: All responses are gathered into an output file.
- Quick Turnaround: Results are usually ready within a day.
What is the pricing for the Batch API?
There are several models available, each offering distinct features at various price levels. Pricing is available per 1 million or 1 thousand tokens. Tokens are segments of words; for example, 1,000 tokens approximately equate to 750 words. This paragraph contains 35 tokens.
Additionally, language models can be accessed through the Batch API, which delivers results within 24 hours at a 50% reduced rate.
What can I do with Batch API?
The Batch API is versatile, supporting a wide range of applications that require bulk data processing, asynchronous task management, or time-intensive computations. This flexibility makes it suitable for various business needs and technological challenges.
Data Analysis and Processing
For businesses that deal with large datasets, the Batch API can perform complex data analysis and processing tasks without the need for real-time interaction.
- Automated Insights: Generate insights from large data sets without manual intervention.
- Efficient Data Handling: Manage and process large volumes of data efficiently.
Machine Learning Model Training
The Batch API is particularly useful for training machine learning models, where large datasets are required and processing can be distributed over time.
- Model Training: Train models using large datasets without straining real-time resources.
- Asynchronous Updates: Update models periodically with new data batches.
Content Generation and Management
Companies that require content generation at scale, such as for marketing or customer support, can use the Batch API to generate large volumes of content efficiently.
- Mass Content Creation: Create content in bulk, such as articles, product descriptions, or reports.
- Resource-Efficient Operations: Reduce the operational load by handling content creation asynchronously.
What’s the limit of how many requests I can batch?
There is no fixed upper limit on the number of requests that can be included in a batch; however, operational efficiency is maintained by managing the queue dynamically.
Token limits: Each batch can contain up to several million tokens, with adjustments possible based on system capacity and demand.
- Queue management: The system manages the queue to optimize processing times and resource allocation.
OpenAI Chooses Tokyo for Its Asia Office
OpenAI has strategically selected Tokyo as the location for its first office in Asia, marking a significant step in its global expansion strategy. Tokyo, known for its blend of technological innovation, strong economy, and a robust talent pool, presents an ideal setting for OpenAI to integrate into the Asian market. This decision underscores OpenAI’s commitment to becoming a key player in the Asian technological landscape, promoting AI advancements and collaborations across the continent.
Also read: What the OpenAI and European Publisher Deals Mean for AI?
Why Did OpenAI Choose Tokyo for Its Asian Office?

OpenAI’s choice of Tokyo as the location for its first Asian office was influenced by multiple strategic factors that align with its long-term goals and operational needs.
- Leading Technological Hub:Tokyo is recognized globally as a leader in technology and innovation, which aligns with OpenAI’s core mission.
- Strategic Geographical Location:Tokyo’s position in Asia makes it a strategic hub for addressing the broader Asian markets.
- Cultural and Economic Dynamics:The cultural and economic dynamics of Tokyo provide a conducive environment for OpenAI’s operations.
The Features of the Custom GPT-4 Model for Japan?
The custom GPT-4 model for Japan has been specifically optimized to meet the unique linguistic and cultural needs of the Japanese market, ensuring more effective and nuanced interactions.
Language Optimization
The model has been fine-tuned to understand and generate Japanese text with high accuracy.
- Improved Language Understanding: Enhanced comprehension of Japanese syntax and semantics.
- Localized Responses: Ability to generate culturally relevant and contextually appropriate responses.
Enhanced Performance
The GPT-4 model for Japan is designed to deliver faster and more efficient performance.
- Speed Improvements: Faster response times compared to previous models.
- Efficiency in Processing: Optimized to handle large volumes of queries efficiently.
Custom Features
Special features have been incorporated to cater specifically to Japanese users and businesses.
- Industry-Specific Customizations: Tailored features for sectors like finance, healthcare, and education.
- Integration Capabilities: Better integration with Japanese business systems and workflows.
Conclusion
OpenAI’s introduction of the Batch API and its establishment of a Tokyo office mark pivotal advancements in its global strategy. The Batch API optimizes AI task processing, enhancing efficiency and reducing costs for global businesses by allowing bulk operations during off-peak times. Meanwhile, choosing Tokyo as its Asian hub leverages the city’s technological leadership and strategic position, promoting regional integration and innovation.
The tailored GPT-4 model for Japan demonstrates OpenAI’s commitment to adapting and serving specific market needs, ensuring its solutions are both relevant and effective. These initiatives not only expand OpenAI’s global presence but also pave the way for further innovations and market expansions, solidifying its leadership in the AI sector.